Moderne Workloads wie KI, maschinelles Lernen und Datenanalyse sind zunehmend auf GPU-Beschleunigung angewiesen. Das Ausführen dieser Anwendungen in der Produktion bringt Komplexitäten wie Treiberkompatibilität, Knotenkonfiguration, Ressourcenplanung und Skalierung mit sich. Der De-facto-Industriestandard ist Kubernetes, auch bekannt als K8s.
Kubernetes und GPUs
Kubernetes eignet sich sehr gut zum Verwalten von Docker-Containern über eine Reihe von Knoten in einem Cluster. Leider werden GPU-Ressourcen nicht nativ unterstützt. Es bietet jedoch sogenannte Geräte-Plugins für den Zugriff auf diese spezialisierte Hardware.
GPU Operator
Der GPU Operator ist Nvidias Implementierung eines Kubernetes-Geräte-Plugins für ihre eigenen GPUs.
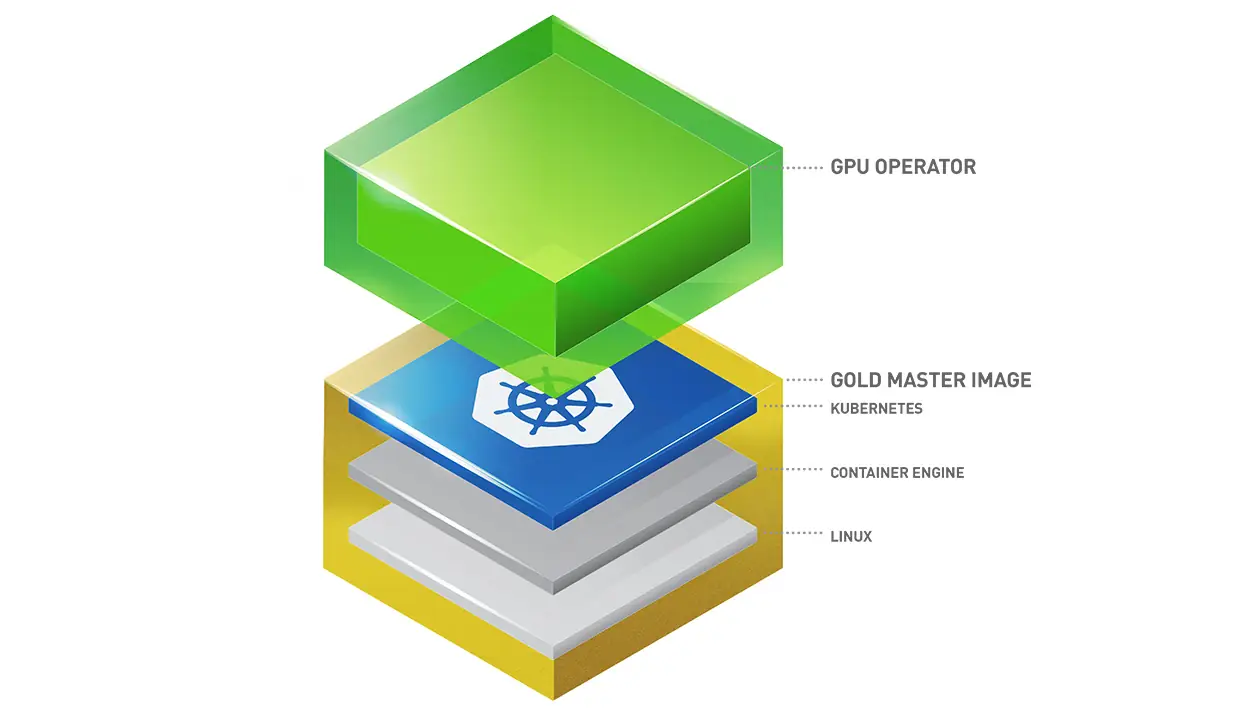
Es gibt einige Dokumentationen zur Installation des Nvidia GPU Operator auf einem Kubernetes-Cluster. Die folgenden Schritte verwenden Helm und konfigurieren die relevanten Einstellungen für eine RKE2-Umgebung. Es ist wichtig zu überprüfen, ob die GPU Operator-Version und der Nvidia-Treiber miteinander kompatibel sind. Beachten Sie, dass bei dieser Bereitstellung der Treiber vom System bereitgestellt werden muss. Nur das Container-Toolkit wird vom GPU Operator bereitgestellt.
- Helm-Repository hinzu fügen
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia helm repo update - GPU Operator in einem separaten Namespace installieren
helm install gpu-operator -n gpu-operator --create-namespace \ nvidia/gpu-operator \ --version=v24.9.1 \ --set driver.enabled=false \ --set toolkit.enabled=true \ --set toolkit.env[0].name=CONTAINERD_CONFIG \ --set toolkit.env[0].value=/var/lib/rancher/rke2/agent/etc/containerd/config.toml \ --set toolkit.env[1].name=CONTAINERD_SOCKET \ --set toolkit.env[1].value=/run/k3s/containerd/containerd.sock \ --set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \ --set toolkit.env[2].value=nvidia \ --set toolkit.env[3].name=CONTAINERD_SET_AS_DEFAULT
Installieren des Treibers
Dieser Schritt hängt vom Betriebssystem ab, auf dem der Kubernetes-Cluster läuft. Für Ubuntu Linux genügt der Befehl:
sudo ubuntu-drivers installTeilen der GPU
Standardmäßig kann jeweils nur ein Container auf die GPU zugreifen. Wenn mehrere Container eine GPU benötigen, kann man entweder mehrere GPUs in einem einzigen Knoten installieren oder dem Cluster weitere Knoten mit GPU-Ressourcen hinzufügen. Beide Optionen sind relativ teuer, da viele Ressourcen ungenutzt bleiben.
In der Praxis nutzt ein Container selten die gesamte Kapazität einer einzelnen GPU. Wenn main mit den Implikationen einverstanden ist, kann man die Funktion Time-Slicing verwenden. Die offizielle Nvidia Dokumentation enthält alle Details, Einschränkungen und Sicherheitsimplikationen. Grundsätzlich müssen man eine ConfigMap auf dem Cluster bereitstellen, die angibt, wie viele virtuelle GPUs (Replikate) bereitgestellt werden sollen. Um die GPU mit 4 Containern zu teilen, konfigurieren man:
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config-all
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4Dann muss man diese Konfiguration im GPU-Operator-Installationsskript von oben übergeben:
helm install gpu-operator -n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v24.9.1 \
--set driver.enabled=false \
--set toolkit.enabled=true \
--set toolkit.env[0].name=CONTAINERD_CONFIG \
--set toolkit.env[0].value=/var/lib/rancher/rke2/agent/etc/containerd/config.toml \
--set toolkit.env[1].name=CONTAINERD_SOCKET \
--set toolkit.env[1].value=/run/k3s/containerd/containerd.sock \
--set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \
--set toolkit.env[2].value=nvidia \
--set toolkit.env[3].name=CONTAINERD_SET_AS_DEFAULT \
--set-string toolkit.env[3].value=true \
--set devicePlugin.config.name=time-slicing-config-all \
--set devicePlugin.config.default=anyÜberprüfen des Setups
Jetzt ist es an der Zeit, die erste GPU-beschleunigte Anwendung zu starten. Nvidia hat einige CUDA-Beispiele in ihrem GitHub-Repository bereitgestellt. Sie sind auch als Docker-Images verfügbar. Das folgende YAML startet einen Pod, der Vektorberechnungen auf der GPU ausführt:
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
runtimeClassName: nvidia
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1Die wichtigen Abschnitte, die sich von regulären Deployments unterscheiden:
- runtimeClassName: nvidia: muss auf den Wert von CONTAINERD_RUNTIME_CLASS gesetzt werden, der in der GPU Operator-Konfiguration verwendet wird
- nvidia.com/gpu: 1: fordert 1 GPU an
Wenn alles geklappt hat, sieht die Ausgabe folgendermaßen aus:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
DoneKurz gesagt
Die Möglichkeit, GPUs in Kubernetes-Clustern zu verwenden, bringt ein hohes Maß an Flexibilität beim Ausführen und Skalieren von GPU-beschleunigten Workloads. Der Weg zum ersten erfolgreichen Deployments ist jedoch schwieriger als er aussieht. Nach erfolgreicher Konfiguration funktioniert Nvidias GPU Operator allerdings einfach gut. Auf jeden Fall zu empfehlen.