Modern workloads like AI, Machine Learning and Data Analytics increasingly rely on GPU acceleration. Running these applications in production, introduces complexities such as driver compatibility, node configuration, resource scheduling and scaling. The defacto industry standard is Kubernetes, also known as K8s.
Kubernetes and GPUs
Kubernetes is very good at managing Docker containers across a set of nodes in a cluster. Unfortunately GPUs resources are not natively supported. It offers, however so called device plugins to access this specialized hardware.
GPU Operator
The GPU Operator is Nvidias implementation of a Kubernetes device plugin for their own GPUs.
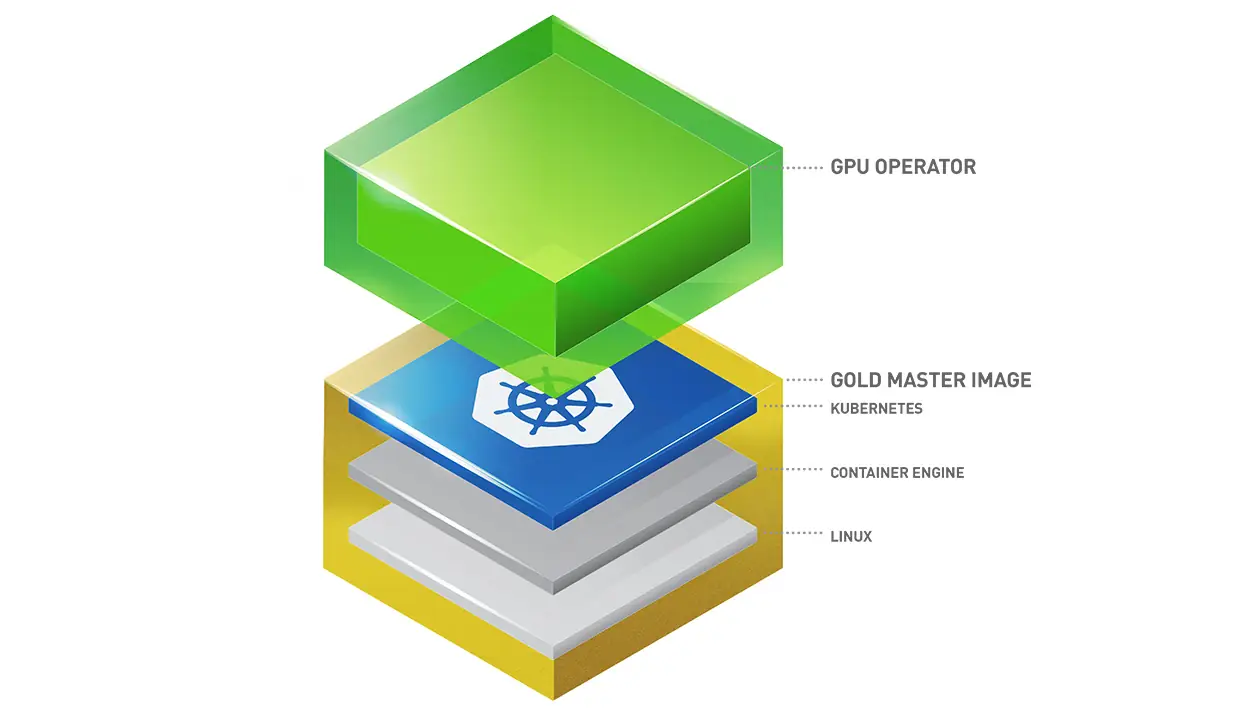
There are a couple of documentations on how to install the Nvidia GPU Operator on a Kubernetes cluster. The following steps use helm and configures the relevant settings for a RKE2 environment. It’s important to check that the GPU Operator version and the Nvidia driver are compatible with each other. Note that with this deployment the driver has to be provided by the system. Only the Container toolkit will be provided by the GPU Operator.
- Add the helm repository
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia helm repo update - Install GPU Operator in a separate namespace
helm install gpu-operator -n gpu-operator --create-namespace \ nvidia/gpu-operator \ --version=v24.9.1 \ --set driver.enabled=false \ --set toolkit.enabled=true \ --set toolkit.env[0].name=CONTAINERD_CONFIG \ --set toolkit.env[0].value=/var/lib/rancher/rke2/agent/etc/containerd/config.toml \ --set toolkit.env[1].name=CONTAINERD_SOCKET \ --set toolkit.env[1].value=/run/k3s/containerd/containerd.sock \ --set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \ --set toolkit.env[2].value=nvidia \ --set toolkit.env[3].name=CONTAINERD_SET_AS_DEFAULT
Installing the driver
This step depends on the OS that your Kubernetes cluster is running on. For Ubuntu Linux it is as simple as typing:
sudo ubuntu-drivers installSharing the GPU
By default, only one container can access the GPU at a time. If multiple containers require a GPU, you can either install more GPUs in a single node or add more nodes with GPU resources to the cluster. Both options are relatively expensive, as many resources remain unused.
In practice, one container rarely uses all the capacity of a single GPU. If you are OK with the implications, you can use a feature called time-slicing. The official Nvidia documentation covers all the details, limitations and security implications. Basically, you need to deploy a ConfigMap onto the cluster which tells how many virtual GPUs (replicas) will become available. To share the GPU with 4 containers you configure:
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config-all
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4Then you need to pass this config in the GPU-Operator installation script from above:
helm install gpu-operator -n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v24.9.1 \
--set driver.enabled=false \
--set toolkit.enabled=true \
--set toolkit.env[0].name=CONTAINERD_CONFIG \
--set toolkit.env[0].value=/var/lib/rancher/rke2/agent/etc/containerd/config.toml \
--set toolkit.env[1].name=CONTAINERD_SOCKET \
--set toolkit.env[1].value=/run/k3s/containerd/containerd.sock \
--set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \
--set toolkit.env[2].value=nvidia \
--set toolkit.env[3].name=CONTAINERD_SET_AS_DEFAULT \
--set-string toolkit.env[3].value=true \
--set devicePlugin.config.name=time-slicing-config-all \
--set devicePlugin.config.default=anyVerifying the setup
Now it’s time to deploy the first GPU-accelerated application. Nvidia developed some CUDA samples in their GitHub repository. They are also available as docker images. The following YAML deploys a pod that executes vector calculation on the GPU:
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
runtimeClassName: nvidia
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1The important sections that differ from regular deployments:
- runtimeClassName: nvidia: has to be set to the value of CONTAINERD_RUNTIME_CLASS used in the GPU Operator deployment
- nvidia.com/gpu: 1: requests 1 GPU
If everything worked out the output looks like this:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
DoneIn a nutshell
Being able to use GPUs in a Kubernetes cluster, offers a great amount of flexibility running and scaling GPU accelerated workloads. The path to the first successful deployment is harder than it looks, though. Once successfully configures, Nvidias GPU Operator just works nicely. Definitely recommended.